Окно настроек поиска и извлечения данных |

|

|
|
Окно настроек поиска и извлечения данных |
|
|
Окно настроек поиска и извлечения данных |
|
|
|
Окно настроек поиска и извлечения данных |
|
|
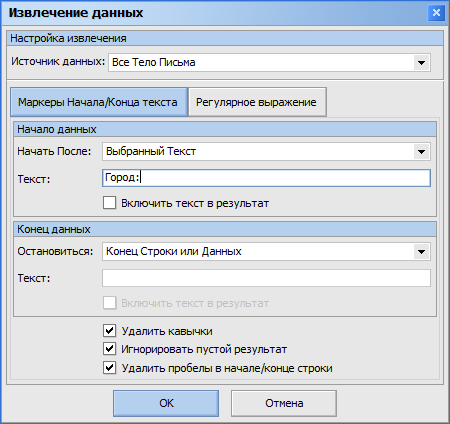
В этом окне задаются настройки поиска и извлечения данных для действия правила обработки почты Извлечь и сохранить данные из письма.
Вы можете добавить в действие несколько "извлекателей" данных, каждый из которых будет искать свои данные в заданном месте письма, после чего извлеченный текст будет сохранен в CSV файл.
Источник данных - в этом поле нужно выбрать, из какого места (части) письма следует извлечь данные (например, Тема (Subject) письма, его содержимое, различные поля заголовка и т.д.).
Далее, необходимо выбрать каким образом будет выполняться поиск текста для извлечения: через поиск маркеров начала/конца текста ИЛИ текст будет извлекаться с помощью регулярного выражения (Regexp'a).
Рассмотрим извлечение через маркеры начала/конца текста:
Начать после - в этом блоке задается с какой позиции необходимо начать извлечение данных.
Начало строки - если выбрана эта опция то данные будут извлекаться с начала выбранного источника данных (например, если выбрана тема письма то выборка начнется с первого символа темы, если содержимое (тело) письма - то с первой строки тела и т.д.).
Выбранный текст - начать извлечение данных только если часть письма содержит некоторый текст, который будет являться маркером начала интересующих вас данных.
Выбранный текст с начала строки - работает аналогично предыдущей опции, но с одним условием: заданный текст будет считаться маркером начала данных только если он находится в начале строки (например, если вы ищите данные в многострочном теле письма - условие сработает если одна из строк начинается с заданного текста и НЕ сработает если он находится где-то в середине строки).
Текст - текст, который который нужно найти и который является маркером начала интересущих вас данных.
Включить текст в результат - нужно ли включать в извлекаемые данные текст (заданный в предыдущем поле), который является маркером начала данных.
Рассмотрим пример работы этих настроек, допустим на входе у нас будут письма с приблизительно таким содержимым:
Клиент: Иванов Иван Иванович; статус: новый
Город: Москва
Заказ: товар 22, артикул: 134222
Сумма: 1000 руб
Если мы хотим извлечь название города из этого текста - то зададим настройки как на скриншоте выше: источник данных - Все тело письма, начать после - Выбранный текст, указываем текст, который является маркером начала данных - Город:
В результате как только программа найдет в содержимом письма подстроку Город: - это будет считаться точкой начала извлечения данных. Если бы мы поставили галку Включить текст в результат - то в результат извлечения данных попал бы текст-маркер начала данных т.е. результатом был бы Город: Москва. Поскольку эта галка не установлена то результатом будет просто Москва.
Остановиться - в этом блоке задаются условия конца извлечения данных, т.е. с какой позиции извлечение нужно остановить.
Конец строки или данных - если данные извлекаются из однострочной части письма (например из Темы) - концом данных будет конец содержимого этой части письма. Если данные извлекаются из многострочной части письма (например тела письма) - то до конца стоки, с которой началось извлечение данных.
Выбранный текст - закончить извлечение данных на позиции, с которой начинается некоторый текст, являющийся маркером окончания данных.
Текст - текст, который будет являться маркером окончания данных.
Включить текст в результат - нужно ли включать текст-маркер окончания данных в результат.
Допустим, нам нужно извлечь имя клиента из примера выше. Обратите внимание, что строка, содержащая имя клиента, содержит не только имя:
Клиент: Иванов Иван Иванович; статус: новый
Режим "Конец строки или данных" в этом случае не подойдет т.к. тогда в результат попадет не только имя, но и статус клиента. Поэтому нужно выбрать опцию остановки Выбранный текст и указать в качестве текста точку с запятой ; которая отделяет имя клиента от его статуса (если будет стоять галка Включить текст в результат - то точка с запятой будет считаться частью извлекаемых данных и попадет в результат).
Удалить кавычки - если извлеченный текст находится в кавычках - то удалить эти кавычки. Например, если бы название города было в таком виде: Город: "Москва" то результатом будет строка Москва без кавычек.
Игнорировать пустой результат - если письмо не содержит текста, удовлетворяющего условиям извлечения Начать после и Остановиться - в результирующий CSV файл не будет сохранен пустой результат т.к. количество столбцов CSV файла будет меньше если в письме не оказалось искомых данных. Если эта галка не выставлена - будет сохранен пустой результат и число полей CSV файла будет у всех строк одинаковым.
Удалить пробелы в начале/конце строки - удалить пробелы по краям извлекаемых данных. Например, в строке Город: Москва есть пробел между двоеточием и названием города. Если эта галка не стоит то результатом будет Москва, а если стоит то Москва
Для извлечения текста с использованием сложных правил поиска вы можете использовать регулярное выражение:
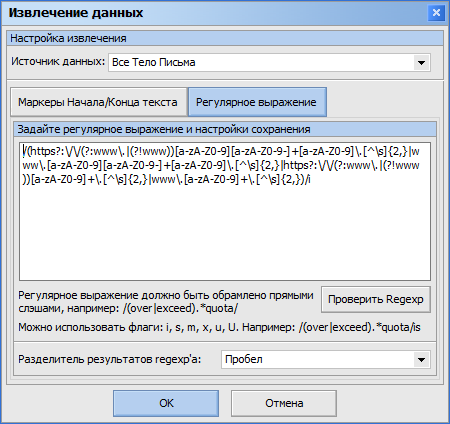
Обратите внимание, что программа считает строку регулярным выражением если оно заключено в прямые слэши - / / Нажмите кнопку Проверить Regexp чтобы открыть окно тестирования регулярного выражения, где вы сможете проверить его работу над образцом данных, над которыми планируется его срабатывание. Если вы хотите использовать regexp для поиска текста, с эмоджи, русскими буквами, азиатскими иероглифами и т.д. - возможно вам потребуется указать флаг /u - unicode для корректного срабатывания regexp'a.
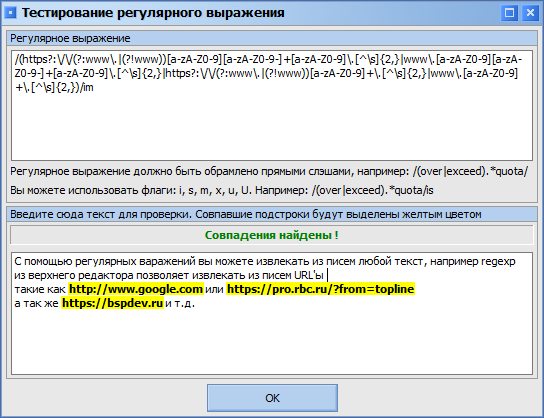
Для функции извлечения текста регулярное выражение используется для извлечения ВСЕХ фрагментов текста, которые под него попадают (т.е. используется метод ExtractAll).
Вы можете добавить в настройки действия извлечь и сохранить данные из письма множество таких "извлекателей" чтобы получить на выходе CSV файл с нужным содержимым и набором полей.
Если вы создали несколько "извлекателей" данных (т.е. вы можете добавить несколько Regexp'ов, которые будут извлекать разные данные из разных частей письма) и при этом регулярные выражения могут возвращать множество совпадений - может быть полезным задать для этих совпадений свой разделитель чтобы они не сломали структуру вашего CSV файла.
Например, вы создали два "извлекателя" - один использует regexp для поиска email адресов, а второй - для поиска URL'oв. В этом случае, в настройках действия извлечь и сохранить данные из письма вы можете задать общий разделитель точку с запятой, а для regexp'ов можете задать разделитель запятую и в этом случае у вас получится такой результат в CSV файле:
emai1@domain.com,email2@domain.com;http://www.url1.com,http://www.url2.com
Как видите, данные, которые вернули regexp'ы разделены запятыми, а сами извлекатели - точкой с запятой.